
In den letzten Jahren hat die Künstliche Intelligenz (KI) beeindruckende Fortschritte erzielt und damit die Anforderungen an die Datenarchitektur grundlegend verändert. Finanzdienstleister setzen KI-Modelle bereits erfolgreich in Bereichen wie Betrugserkennung, Risikoanalyse und der Automatisierung interner Prozesse ein. Doch diese Anwendungen können nur so gut sein wie die Daten, auf denen sie basieren. Eine robuste Datenarchitektur bildet das unverzichtbare Fundament für die Entwicklung, das Training und die Anwendung von KI-Lösungen. Bei der Gestaltung einer solchen Architektur spielen mehrere Aspekte eine wesentliche Rolle. Neben der technischen Infrastruktur, wie Data Lakes und Data Warehouses, sind auch fachliche Perspektiven wie bspw. der Datenschutz von zentraler Bedeutung.
In diesem Artikel wird die Bedeutung einer durchdachten Datenarchitektur für KI-Anwendungen genauer untersucht. Der Fokus liegt dabei auf der kritischen Rolle qualitativ hochwertiger Daten, die für das erfolgreiche Training und die zuverlässige Leistung von KI-Modellen unerlässlich sind. Im Folgenden werden die grundlegenden Voraussetzungen für eine effektive KI-Datenarchitektur, die Herausforderungen bei der Datenerfassung und Modellbewertung sowie die zentralen Fragestellungen, die bei der Einführung solcher Systeme zu berücksichtigen sind, näher beleuchtet. Ein Ausblick auf zukünftige Entwicklungen rundet die Betrachtung ab.
Bedeutung der Daten für die KI-Entwicklung
Daten sind das Herzstück jeder KI-Anwendung. Sie sind entscheidend für das Training von Modellen, die letztendlich die Leistung und Genauigkeit der KI bestimmen. Hochwertige, aktuelle und relevante Daten sind notwendig, um genaue Vorhersagen zu treffen. Somit ist die KI-Datenarchitektur ein elementarer Baustein für den erfolgreichen Einsatz von KI-Modellen. Sie unterscheidet sich von der traditionellen Datenarchitektur durch ihre spezifischen Anforderungen an Datenmanagement-Tools, technische Infrastruktur (u.a. Cloud-Nutzung) sowie Datenintegration und -verarbeitung. Die Architektur umfasst Datenbanken und Speichersysteme, die speziell für die Bedürfnisse von KI-Anwendungen optimiert sind, sowie die Integration von Daten aus unterschiedlichen Quellen, um präzise und zuverlässige Modelle zu entwickeln sowie konkreten Nutzen aus einzelnen KI-Lösungen zu ziehen.
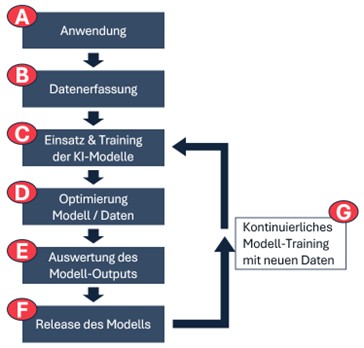
Abbildung 1 veranschaulicht den typischen Prozess bei der Entwicklung und Implementierung von KI-Modellen. Der Prozess beginnt mit der Definition der Anwendung (A), für den die KI entwickelt werden soll. Dieses Anwendungsszenario legt den Grundstein für den gesamten weiteren Ablauf, da sie bestimmt, welche Daten benötigt werden und wie das KI-Modell aufgebaut sein muss. Im nächsten Schritt werden die relevanten Daten erfasst bzw. gesammelt und vorbereitet (B). Die Daten sind entscheidend, da sie die Grundlage für das Training des KI-Modells bilden. Es ist wichtig, dass die Daten auf die Problemstellung abgestimmt sind, um ein präzises und effektives Modell zu entwickeln. Im nachfolgenden Abschnitt wird dieser Schritt daher noch einmal im Detail beleuchtet.
Anschließend folgt der Schritt des Einsatzes und des Trainings von KI-Modellen (C). In dieser Phase werden verschiedene Modelle entwickelt und getestet, um die beste Leistung zu erzielen. Die initiale Wahl des Modells kann dabei anhand der zugrundeliegenden Lernverfahren der KI erfolgen, welche im unteren Teil des Artikels detaillierter vorgestellt werden. Das Training erfolgt iterativ, wobei die Modelle ständig optimiert werden. Sollte ein Modell nicht die erwarteten Ergebnisse liefern, erfolgt eine Optimierung sowohl des Modells als auch der Daten (D), um sicherzustellen, dass das Modell besser auf die Problemstellung abgestimmt ist. Eine typische Herausforderung beim Trainieren von Modellen ist das sog. Over- oder Underfitting, das ebenfalls im unteren Teil dieses Beitrags beschrieben wird.
Die Auswertung des Modell-Outputs (E) ist der nächste Schritt. Hier wird überprüft, ob das Modell die gewünschten Resultate liefert und ob es für den praktischen Einsatz geeignet ist. Wenn das Modell alle Anforderungen erfüllt, wird es schließlich veröffentlicht und in die reale Umgebung überführt (F).
Das kontinuierliche Training mit neuen Daten (G) sichert den langfristigen Erfolg des Modells und gewährleistet zukünftig seine Anpassungsfähigkeit an neue Bedingungen. Dieser gesamte Workflow ist ein dynamischer Prozess, bei dem die Rückkopplung aus späteren Phasen zu Anpassungen in den früheren Schritten führen kann, wodurch das Modell flexibel und leistungsfähig bleibt.
Herausforderungen für die Datenarchitektur
Diese neue Prozessstruktur für den KI-Einsatz bringt drei zentrale Herausforderungen mit, die durch die Datenarchitektur zu überwinden sind:
- Datenmanagement-Tools: Traditionelle Datenmanagement-Tools sind oft nicht in der Lage, die Formatvielfalt und das Volumen der Daten zu bewältigen, die für KI-Anwendungen erforderlich sind. KI-Datenarchitekturen verwenden spezialisierte Tools, die auf die Verarbeitung und Analyse großer Datenmengen ausgelegt sind. Dazu gehören auch die Infrastruktur und Auswahl der notwendigen Speichersysteme (bspw. Data Warehouse oder Data Lake).
- Infrastruktur: Während traditionelle Systeme oft auf On-Premise-Servern aufbauen, nutzen KI-Datenarchitekturen die Skalierbarkeit und Flexibilität der Cloud, um große Datenmengen zu speichern und zu verarbeiten sowie Rechenressourcen dynamisch bereitzustellen.
- Datenintegration und -verarbeitung: KI-Datenarchitekturen müssen in der Lage sein, Daten aus verschiedensten Quellen zu integrieren und in Echtzeit zu verarbeiten. Dies erfordert den Einsatz moderner Technologien, standardisierte Schnittstellen und Streaming-Plattformen, die in traditionellen Architekturen oft nicht vorhanden sind.
Entsprechend ist es notwendig KI-Modelle und Daten aufeinander abzustimmen. Modelle sind so auszuwählen, dass sie für die spezifischen Anwendungsfälle geeignet sind, um diese mit ausreichenden und qualitativ hochwertigen Daten zu trainieren. Darüber hinaus müssen kontinuierliche Optimierungs- und Anpassungsprozesse etabliert werden, um die Modelle aktuell und leistungsfähig zu halten. KI-Datenarchitekturen unterstützen diesen Prozess durch die Bereitstellung geeigneter Werkzeuge und Plattformen für das Modell-Management und die Automatisierung von Trainingsprozessen.
KI-Datenarchitektur und KI-Entwicklungsprozesse
Die im folgenden gezeigte Abbildung 2 zeigt die grundlegende KI-Datenarchitektur. Die beiden Hauptbestandteile der Architektur, Datenerfassung sowie Einsatz und Training der KI-Modelle, werden in diesem Abschnitt detailliert erläutert. Wie zu Beginn des Beitrags bereits skizziert, erfolgt die Auswahl des KI-Modells an den zugrundeliegenden Lernverfahren, die ergänzt um primäre Herausforderungen in der Nutzung und deren Optimierungsansätze ebenfalls vorgestellt werden. Die Betrachtung wird komplettiert um eine Auswahl an Anwendungsfälle aus der Finanzdienstleistungsbranche.
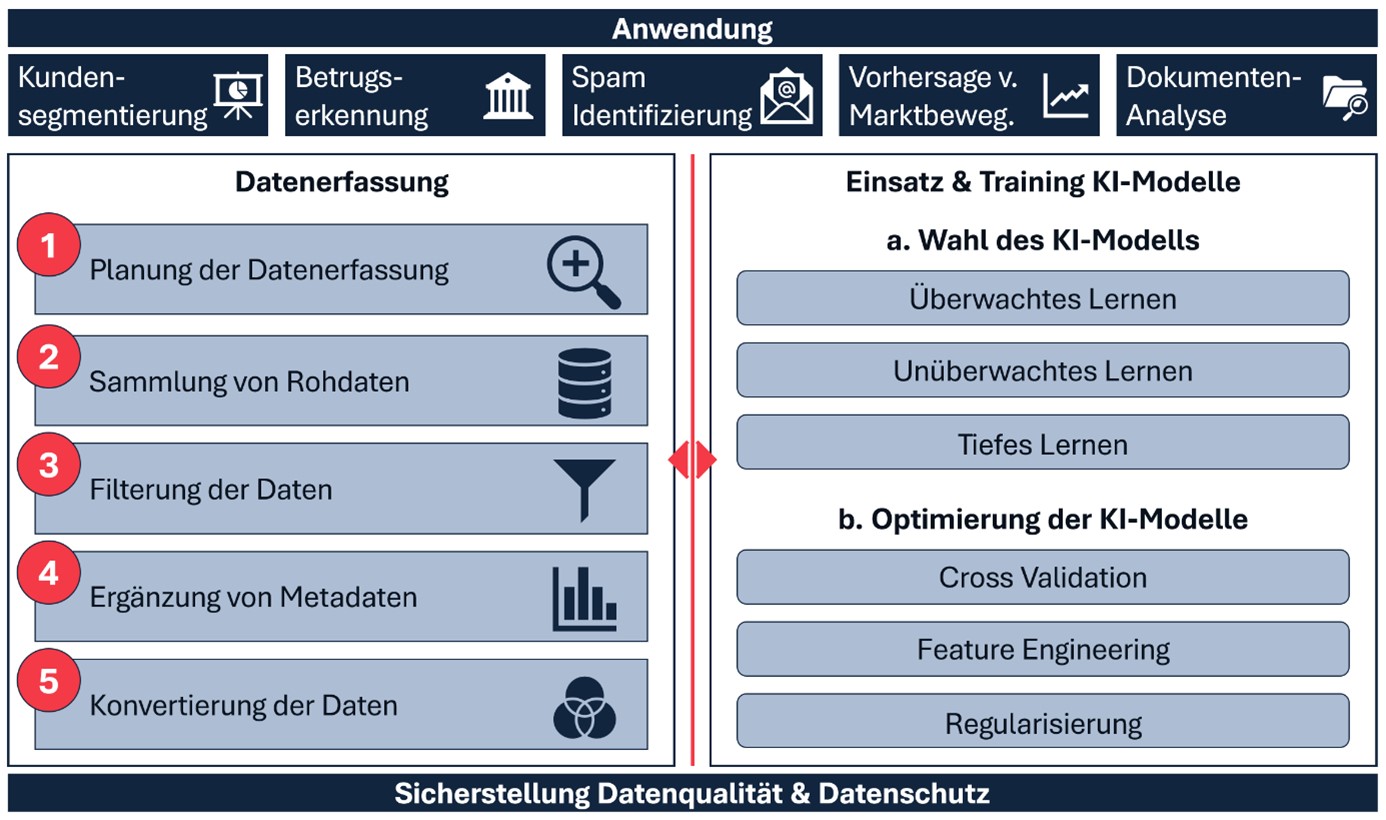
Datenerfassung
Regelmäßige Datenerfassung stellt sicher, dass die KI-Modelle stets mit den neuesten Informationen arbeiten. Dies verbessert die Genauigkeit und Relevanz der Ergebnisse. Zur Sammlung von Daten werden am Markt häufig Data Lakes eingesetzt, um die Daten aus unterschiedlichen Datenquellen miteinander zu kombinieren und zu speichern. Die Definition und Auswahl der Technologien für das Repository sind jedoch hoch individuell. Data Lakes spiegeln dabei nur einen möglichen Ansatz zur Umsetzung der erforderlichen Datenbank wider.
Die Auswahl der richtigen Datenquellen ist entscheidend. Sowohl interne als auch externe Datenquellen müssen berücksichtigt werden, wobei manuelle und automatisierte Ansätze zur Datenerfassung kombiniert werden sollten, um hochwertige Daten zu sichern. Vorbereitend müssen anhand des Geschäftsmodells bzw. der zu lösenden Problemstellung die richtigen Daten ausgewählt, in das richtige Format konvertiert und skaliert werden, um das Modell trainieren zu können. Die Datenerfassung an sich ist ein komplexer Vorgang, der aus fünf Schritten besteht:
- Planung der Datenerfassung: Die Planung beginnt mit der Definition der Ziele und Anforderungen des Projekts. Es wird entschieden, welche Daten in welcher Qualität benötigt werden und aus welchen Quellen diese stammen sollen. Diese Phase umfasst auch die Festlegung der Methoden und Technologien, die zur Datenerfassung verwendet werden, sowie die Identifikation von Verantwortlichkeiten und Zeitplänen.
- Sammlung von Rohdaten: In diesem Schritt werden die identifizierten Datenquellen aktiv genutzt, um Rohdaten zu sammeln. Dies kann durch verschiedene Methoden geschehen, wie manuelle Eingaben, APIs oder Web-Crawler. Die Sammlung der Rohdaten ist oft eine kontinuierliche oder bedarfsgesteuerte Aktivität, je nach Projektanforderung.
- Filterung der Daten: Nach der Sammlung werden die Rohdaten gereinigt, um Redundanzen zu entfernen. Dies kann durch verschiedene Techniken wie statistische Methoden oder manuelle Überprüfung geschehen. Ziel ist es, die Datenqualität zu verbessern und sicherzustellen, dass die verbleibenden Daten für die Analyse geeignet sind.
- Ergänzung von Metadaten: Die Ergänzung von Metadaten – auch Datenannotation genannt – ist der Prozess des Hinzufügens von Informationen wie Datum, Ort oder Zeit zu den gesammelten Daten. Dies erleichtert die spätere Analyse, insbesondere bei maschinellen Lernalgorithmen, die auf Daten angewiesen sind. Annotation kann manuell oder automatisiert erfolgen und ist oft ein zeitaufwändiger, aber kritischer Schritt.
- Konvertierung der Daten: In der Datenvorbereitung werden die ausgewählten Daten in das richtige Format konvertiert. Dies beinhaltet die Überführung von unterschiedlichen Daten in ein einheitliches Dateiformat. Dabei werden bisherige Datenmerkmale überschrieben, um Vergleichbarkeit sowie Skalierbarkeit herzustellen und in den nachfolgenden Modelleinsätzen die notwendige Genauigkeit zu gewährleisten. Diese Phase schließt den Datenerfassungsprozess ab und stellt sicher, dass die Daten zur Verwendung z.B. im Training von KI-Modellen bereit sind.
Einsatz und Training von KI-Modellen – Wahl des KI-Modells
Im Kern der Datenarchitektur stehen KI-Modelle, die in der Finanzbranche eingesetzt werden, um Vorhersagen zu treffen, Betrug zu bekämpfen, Risiken zu managen oder die Kundenbetreuung zu verbessern. Wie bereits beschrieben ist die Wahl des richtigen Algorithmus von den spezifischen Eigenschaften der Daten und der initialen Problemstellung bzw. der geplanten Anwendung abhängig. KI-Modelle und Algorithmen lassen sich Lernverfahren zuordnen. Die drei verbreitetsten Lernverfahren werden im Folgenden erläutert, um zu verdeutlichen, welche Rolle die Daten bei der KI integrierten Architektur spielen.
- Überwachtes Lernen: Ein maschinelles Lernverfahren, bei dem das Modell aus einem Trainingsdatensatz lernt, der sowohl Eingabedaten als auch die zugehörigen richtigen Ausgaben (Labels) enthält. Das Ziel des überwachten Lernens ist es, eine Funktion zu erlernen, die die Eingaben zu den richtigen Ausgaben abbildet. Die Trainingsdaten enthalten also Paare von Eingabedaten und entsprechenden Ausgaben, auf dessen Basis dann die Vorhersage oder Klassifikation neuer, unbekannter Daten erstellt werden kann.
Beispiele für Algorithmen dieses Lernverfahrens sind Lineare Regressionen, Logistische Regressionen, Entscheidungsbäume, Support Vector Machines (SVMs) oder einfache Neuronale Netze. Anwendungsbeispiele aus der Finanzdienstleistungsbranche sind die Klassifikation von E-Mail-Spam oder die Vorhersage von Preisen bzw. Aktienkursen. - Unüberwachtes Lernen: Ein weiteres maschinelles Lernverfahren, bei dem das Modell aus einem Datensatz ohne vorgegebene Ausgaben (Labels) lernt. Das Ziel des unüberwachten Lernens ist es, Muster oder Strukturen in den Daten zu entdecken. Die Trainingsdaten enthalten nur Eingabedaten ohne zugehörige Ausgaben. Das Modell versucht, Gruppen, Muster oder Strukturen in den Daten zu identifizieren.
Beispiele für Algorithmen dieses Lernverfahrens sind K-Means Clustering, Hierarchisches Clustering und Methoden zur Anomalieerkennung. Anwendungsbeispiele aus der Finanzdienstleistungsbranche sind die Kundensegmentierung, bei der Kunden in verschiedene Gruppen eingeteilt werden, und die Anomalieerkennung, die zur Erkennung ungewöhnlicher Transaktionen oder möglicher Betrugsfälle verwendet wird. - Tiefes Lernen: Dieses Lernverfahren ist ein Teilbereich des maschinellen Lernens, der auf neuronalen Netzen mit vielen Schichten (sogenannten Deep Neural Networks) basiert. Diese Modelle sind in der Lage, komplexe Muster und Zusammenhänge in großen Datensätzen zu erkennen. Ein tiefes Lernmodell besteht aus mehreren Schichten von Neuronen, einschließlich Eingabe-, versteckten und Ausgabeschichten. Das Ziel ist das automatische Lernen von Merkmalsrepräsentationen aus den Daten.
Beispiele für Architekturen dieses Lernverfahrens sind insb. unterschiedliche komplexe Neuronale Netze. Anwendungsbeispiele aus der Finanzdienstleistungsbranche sind die Analyse von Finanzdokumenten und Vertragsdaten mittels Bilderkennungstechniken sowie die Vorhersage von Marktbewegungen und Risikobewertungen durch die Analyse von Zeitreihen.
Der Einsatz von überwachten, unüberwachten und tiefen Lernverfahren bringt jeweils spezifische Herausforderungen in Bezug auf die Daten mit sich, die bei der Entwicklung der Datenarchitektur berücksichtigt werden müssen.
Das manuelle Labeling für überwachte Modelle kann zeitaufwendig und teuer sein und erfordert zudem eine klare Definition der Label. Beispielsweise sind für die Klassifikation von Kreditrisiken historische Daten notwendig, die klar als „gut“ oder „schlecht“ gekennzeichnet sind. Wie „gut“ oder „schlecht“ definiert ist, muss jedoch eindeutig etabliert sein.
Bei den unüberwachten Modellen liegt die Herausforderung in der Beurteilung der Leistung und Richtigkeit der gefundenen Muster, da es beim Einsatz dieser Modelle keine beschrifteten Daten gibt. Beispielsweise ist es bei der Kundensegmentierung schwierig zu beurteilen, ob die gefundenen Gruppen wirklich sinnvoll sind.
Bei tiefen Lernmodellen ist die Vorverarbeitung und Normalisierung von Daten entscheidend. So müssen Finanzdaten oft logarithmiert oder anderweitig transformiert werden, um stabile Lernprozesse in Neuronalen Netzen zu ermöglichen.
Übergreifend können KI-Modelle zudem überangepasst (Overfitting) oder unterangepasst (Underfitting) sein. Überanpassung tritt auf, wenn das Modell die Daten zu gut kennt und sich zu sehr an ihnen orientiert. Ein Modell zur Vorhersage von Aktienkursen, das zu sehr auf historische Daten optimiert ist, könnte dann beispielsweise zukünftige Trends nicht korrekt vorhersagen, da die Ausgaben nicht generalisiert werden können. Unteranpassung hingegen bedeutet, dass nicht ausreichend Trainingsdaten für das Modell genutzt worden sind, nicht genug trainiert wurde, um Strukturen in den Daten zu erkennen oder das Modell nicht über die notwendige Komplexität verfügt. Es werden daher generell schlechte Ergebnisse erzielt.
Einsatz und Training von KI-Modellen – Optimierung
Die Auswertung des Outputs der KI-Lösung erfolgt durch verschiedene Metriken. Bei einer hohen Abweichung zwischen Ergebnissen aus dem Training und Durchführung von Testfällen kann Overfitting vermutet werden. Indikatoren für Underfitting sind niedrige Genauigkeit sowohl im Training als auch im Test. Anpassungen können bspw. durch Cross-Validation, Feature Engineering oder die Regularisierung des Modells vorgenommen werden.
Die oft genutzte Cross-Validation (Kreuzvalidierung) ist eine Technik, bei der das Modell mehrmals getestet wird, um sicherzustellen, dass es gut arbeitet und nicht nur zufällig gute Ergebnisse liefert. Beim Feature Engineering wird geprüft, ob das Hinzufügen von relevanten Merkmalen (Features) zu einer besseren Modellleistung führt. Regularisierung bedeutet, dass das Modell durch Einsetzen bestimmter Regeln bei der Erstellung von Ergebnissen gesteuert wird, um passendere Ausgaben zu erzeugen.
Die Einwertung von KI-Modellen kann darüber hinaus über unterschiedliche Metriken erfolgen. Wichtige Messwerte sind Genauigkeit (wie oft das Modell richtig liegt), Präzision (wie genau die Vorhersagen sind), Rückruf (wie gut das Modell positive Fälle findet) und der F1-Score (eine Kombination aus Präzision und Rückruf). Bei Modellen, die Zahlen vorhersagen, stehen Messwerte wie u.a. der durchschnittliche Fehler im Vordergrund.
Es ist zudem wichtig, die Leistung des Modells in Echtzeit zu überwachen, besonders wenn das Modell in der Produktivumgebung eingesetzt wird. Techniken wie A/B-Tests (Vergleich von zwei Modellversionen), Erkennung von Datenänderungen und ständige Überprüfung der Modellleistung helfen, Probleme frühzeitig zu erkennen. Beispielsweise ist bei Kreditrisikobewertung die Präzision besonders wichtig, um sicherzustellen, dass ein Kunde, der als kreditwürdig eingestuft wird, tatsächlich auch kreditwürdig ist.
Leitfragen für eine robuste KI-Datenarchitektur
Eine strukturierte Übersicht über die zentralen Fragestellungen, die bei der Implementierung von KI-Datenarchitekturen berücksichtigt werden müssen, ist in Abbildung 3 gegeben.
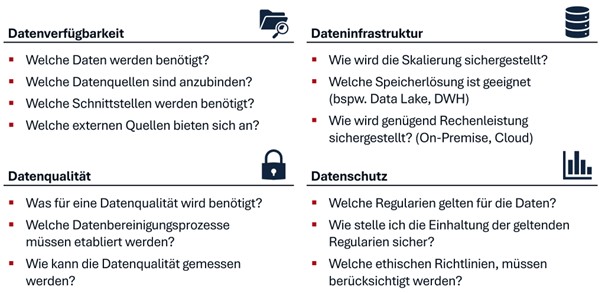
Die Leitfragen gliedern sich in vier Hauptbereiche: Datenverfügbarkeit, Dateninfrastruktur, Datenqualität und Datenschutz. Jeder dieser Bereiche umfasst die wesentlichen Fragen, die Unternehmen bei der Planung und Umsetzung ihrer Datenstrategien beantworten müssen. Wie in diesem Artikel dargestellt, helfen sie dabei, sicherzustellen, dass die Daten effektiv genutzt werden können.
Fazit
Die Fortschritte in der Künstlichen Intelligenz haben die Anforderungen an die Datenarchitektur grundlegend verändert. Eine robuste und flexible KI-Datenarchitektur ist essenziell, um hochwertige, aktuelle und relevante Daten zu verwalten, die für das Training und den Einsatz von KI-Modellen entscheidend sind. Die spezifischen Anforderungen an Datenmanagement-Tools, Infrastruktur und Datenintegration machen deutlich, dass traditionelle Datenarchitekturen nicht ausreichen, um die modernen Anforderungen von KI abzudecken. Bei der Einführung von KI sind in der Datenarchitektur folgende Herausforderungen vordringlich zu adressieren:
- Management großer und divers strukturierter bzw. unstrukturierter Datenmengen
- Integration der Lösung in die Gesamtlandschaft sowie kontinuierliche Optimierung der Modelle
- Einhaltung von Datenqualitätsstandards und Datenschutzrichtlinien
Wir empfehlen, unternehmensweite Standards in Bezug auf Daten, Qualität und Verortung in der Organisation bereits vor dem Einsatz von KI zu schaffen. Langfristige Investitionen in Infrastruktur und die Entwicklung standardisierter Schnittstellen zur Harmonisierung der Datenquellen treiben den Einsatz von KI-Lösungen maßgeblich voran. Durch kontinuierliche Anpassung und Verbesserung der KI-Datenarchitektur können Unternehmen den vollen Nutzen aus KI-Anwendungen ziehen. Unternehmen, die in ihre Datenarchitektur investieren und sie stetig weiterentwickeln, sind optimal aufgestellt, um die Potenziale der KI auszuschöpfen und langfristig wettbewerbsfähig zu bleiben.
